Projekt:2023/Maschinelles Lernen: Unterschied zwischen den Versionen
Ngb (Diskussion | Beiträge) |
Ngb (Diskussion | Beiträge) |
||
| (12 dazwischenliegende Versionen desselben Benutzers werden nicht angezeigt) | |||
| Zeile 335: | Zeile 335: | ||
=== Übungen Spielbäume === | === Übungen Spielbäume === | ||
{{Aufgabe:Start}} | {{Aufgabe:Start}} | ||
# Erstelle einen vollständigen Spielbaum zum [[ | # Erstelle einen vollständigen Spielbaum zum [[wikipedia:Nim-Spiel|Nim-Spiel]] mit fünf Hölzern. ([https://www.alraft.de/altenhein/spiele/nim-spiel/index.html Online-Version des Spiels].) | ||
# Erkläre, wie eine Maschine anhand eines Spielbaums ein Spiel "lernen" kann. | # Erkläre, wie eine Maschine anhand eines Spielbaums ein Spiel "lernen" kann. | ||
# Erläutere, ob mithilfe eines Spielbaums jedes Spiel "perfekt" gespielt werden kann. | # Erläutere, ob mithilfe eines Spielbaums jedes Spiel "perfekt" gespielt werden kann. | ||
| Zeile 342: | Zeile 342: | ||
=== Übungen Entscheidungsbäume === | === Übungen Entscheidungsbäume === | ||
{{Aufgabe:Start}} | {{Aufgabe:Start}} | ||
<ol> | |||
<li>Entscheide anhand des Entscheidungsbaums, welche Äpfelsorten Früchte tragen werden.<br/> | |||
[[Bild:Entscheidungsbaum.png|center|300px]] | |||
{| {{prettytable}} | {| {{prettytable}} | ||
! Alter !! Sorte !! Boden !! Trägt Früchte? | ! Alter !! Sorte !! Boden !! Trägt Früchte? | ||
| Zeile 357: | Zeile 359: | ||
|- | |- | ||
| alt || veredelt || reichhaltig || | | alt || veredelt || reichhaltig || | ||
|} | |}</li> | ||
<li>Erstelle anhand der Tabelle mit Trainingsdaten einen Entscheidungsbaum, der entscheidet, ob wir morgen Tennis spielen gehen wollen, oder nicht. Wende dann Deinen Baum auf die Testdaten in der zweiten Tabelle an.<br/> | |||
Beurteile dann die Güte Deines Baumes und welche Probleme es gibt. <br/> | |||
Welche Rückschlüsse lassen sich aus diesem Beispiel für die Auswahl von Trainingsdaten ziehen? | |||
{| {{prettytable}} | {| {{prettytable}} | ||
|+ Traininsgdaten | |+ Traininsgdaten | ||
| Zeile 413: | Zeile 416: | ||
| sonnig || heiß || gering || schwach || | | sonnig || heiß || gering || schwach || | ||
|} | |} | ||
</li> | |||
<li>Auf der Seite [https://www.inf-schule.de/kids/computerinalltag/entscheide-wie-eine-KI inf-schule.de] findest Du eine digitale Version der Lebensmittelkarten aus dem Unterricht. Durchlaufe den Pfad und entwickele einen Entscheidungsbaum unter der Fragestellung "Welche Lebensmittel sind besonders lecker?" (anstatt "welche sind gesund").<br/> | |||
Welche Kriterien gelten für die Wahl einer Entscheidungskategorie und eines guten Schwellwerts? | |||
</li> | |||
</ol> | |||
{{Aufgabe:End}} | {{Aufgabe:End}} | ||
{{Lösung:Start}} | |||
<ol> | |||
<li> | |||
{| {{prettytable}} | |||
! Alter !! Sorte !! Boden !! Trägt Früchte? | |||
|- | |||
| alt || veredelt || mager || '''ja''' | |||
|- | |||
| alt || natürlich || reichhaltig || '''ja''' | |||
|- | |||
| jung || veredelt || reichhaltig || '''nein''' | |||
|- | |||
| alt || natürlich || mager || '''nein''' | |||
|- | |||
| alt || veredelt || reichhaltig || '''ja''' | |||
|} | |||
</li> | |||
<li>Bei der Auswahl der Trainingsdaten ist es wichtig alle möglichen Ausprägungen der Merkmale in ausreichender Menge zu berücksichtigen. Gibt es Ausprägungen, die in den Trainingsdaten fehlen, dann kann ein Entscheidungsbaum auch nicht lernen, welche Entscheidungen bei dieser Ausprägung getroffen werden müssen. | |||
Im Beispiel kommt die Ausprägung "gering" des Merkmals "Feuchtigkeit" nicht in den Trainingsdaten vor, aber in den Testdaten schon. Dies kann zu unvorhergesehenen / ungewünschten Ergebnissen führen. | |||
</li> | |||
<li>...</li> | |||
</ol> | |||
{{Lösung:End}} | |||
=== Übungen Neuronale Netze === | === Übungen Neuronale Netze === | ||
{{Aufgabe:Start}} | {{Aufgabe:Start}} | ||
# Gib jeweils | # Gib jeweils Gewichte und Schwellwerte an, sodass das gezeigte Neuron bei möglichen Eingaben <code>0</code> und <code>1</code> für jeden der drei Eingänge | ||
## ein <code>UND</code>-Gatter nachbildet, | ## ein <code>UND</code>-Gatter nachbildet, | ||
## ein <code>ODER</code>-Gatter nachbildet, | ## ein <code>ODER</code>-Gatter nachbildet, | ||
| Zeile 435: | Zeile 465: | ||
* Forme die vier Gleichungen in drei oder vier passende Ungleichungen um (im dritten Fall sind es auch vier!). | * Forme die vier Gleichungen in drei oder vier passende Ungleichungen um (im dritten Fall sind es auch vier!). | ||
* Verknüpfe die vier Ungleichungen mit passenden <code>UND</code>-Neuronen (siehe Aufgabe 1). Im dritten Fall musst Du noch ein zusätzliches <code>ODER</code>-Neuron benutzen. | * Verknüpfe die vier Ungleichungen mit passenden <code>UND</code>-Neuronen (siehe Aufgabe 1). Im dritten Fall musst Du noch ein zusätzliches <code>ODER</code>-Neuron benutzen. | ||
{{Tipp:End}}{{Lösung:Start|Aufgabe 2.1}} | {{Tipp:End}} | ||
{{Lösung:Start|Aufgabe 2.1 - Gleichungen}} | |||
Drei Gleichungen aufstellen: | Drei Gleichungen aufstellen: | ||
| Zeile 441: | Zeile 473: | ||
# <math>y = -0,5x + 3</math> | # <math>y = -0,5x + 3</math> | ||
# <math>y = -7x + 35</math> | # <math>y = -7x + 35</math> | ||
{{Lösung:End}}{{Lösung:Start|Aufgabe 2.1 - Ungleichungen}} | |||
Zu drei Ungleichungen umformen: | Zu drei Ungleichungen umformen: | ||
| Zeile 447: | Zeile 479: | ||
# <math>0,5x + y > 3</math> | # <math>0,5x + y > 3</math> | ||
# <math>-7x - y > -35</math> | # <math>-7x - y > -35</math> | ||
{{Lösung:End}}{{Lösung:Start|Aufgabe 2.1 - Neuronales Netz}} | |||
[[Bild:ML_NN_Entwickeln_1_Loseung.png]] | [[Bild:ML_NN_Entwickeln_1_Loseung.png|center|600px]] | ||
{{Lösung:End}}{{Lösung:Start|Aufgabe 2.2}} | {{Lösung:End}} | ||
{{Lösung:Start|Aufgabe 2.2 - Gleichungen}} | |||
Vier Gleichungen aufstellen: | Vier Gleichungen aufstellen: | ||
| Zeile 456: | Zeile 489: | ||
# <math>y = -2,5x + 5</math> | # <math>y = -2,5x + 5</math> | ||
# <math>y = 2,5x - 5</math> | # <math>y = 2,5x - 5</math> | ||
{{Lösung:End}}{{Lösung:Start|Aufgabe 2.2 - Ungleichungen}} | |||
Zu vier Ungleichungen umformen: | Zu vier Ungleichungen umformen: | ||
| Zeile 463: | Zeile 496: | ||
# <math>2,5x + y > 5</math> | # <math>2,5x + y > 5</math> | ||
# <math>-2,5x + y > -5</math> | # <math>-2,5x + y > -5</math> | ||
{{Lösung:End}}{{Lösung:Start|Aufgabe 2.2 - Neuronales Netz}} | |||
[[Bild:ML_NN_Entwickeln_2_Loseung.png]] | [[Bild:ML_NN_Entwickeln_2_Loseung.png|center|600px]] | ||
{{Lösung:End}}{{Lösung:Start|Aufgabe 2. | {{Lösung:End}} | ||
{{Lösung:Start|Aufgabe 2.3 - Gleichungen}} | |||
Zwei Gleichungen aufstellen: | Zwei Gleichungen aufstellen: | ||
# <math>y = 0,5x + 0,5</math> | # <math>y = 0,5x + 0,5</math> | ||
# <math>y = -2x + 8</math> | # <math>y = -2x + 8</math> | ||
{{Lösung:End}}{{Lösung:Start|Aufgabe 2.3 - Ungleichungen}} | |||
Zu vier Ungleichungen umformen, von denen jeweils zwei die beiden Dreiecksflächen einschließen: | Zu vier Ungleichungen umformen, von denen jeweils zwei die beiden Dreiecksflächen einschließen: | ||
| Zeile 477: | Zeile 511: | ||
# <math>y < 0,5x + 0,5 \Leftrightarrow 0,5x - y > -0,5</math> | # <math>y < 0,5x + 0,5 \Leftrightarrow 0,5x - y > -0,5</math> | ||
# <math>y > -2x + 8 \Leftrightarrow 2x + y > 8</math> | # <math>y > -2x + 8 \Leftrightarrow 2x + y > 8</math> | ||
{{Lösung:End}}{{Lösung:Start|Aufgabe 2.3 - Neuronales Netz}} | |||
Die erste und zweite und die zweite und dritte Ungleichung schließen jeweils eine der beiden Dreiecksflächen ein. Sie werden durch ein <code>UND</code>-Neuron verknüpft. (Da immer alle Neuronen einer Schicht eine Verbindung zu allen Neuronen der nachfolgenden Schicht haben, setzen wir die Gewichte der beiden "unnötigen" Verbindungen einfach auf <code> 0</code>.) | Die erste und zweite und die zweite und dritte Ungleichung schließen jeweils eine der beiden Dreiecksflächen ein. Sie werden durch ein <code>UND</code>-Neuron verknüpft. (Da immer alle Neuronen einer Schicht eine Verbindung zu allen Neuronen der nachfolgenden Schicht haben, setzen wir die Gewichte der beiden "unnötigen" Verbindungen einfach auf <code> 0</code>.) | ||
Der Output der beiden <code>UND</code>-Neuronen wird durch ein <code>ODER</code>-Neuron zusammengeführt. Wir erhalten also insgesamt vier Schichten. | Der Output der beiden <code>UND</code>-Neuronen wird durch ein <code>ODER</code>-Neuron zusammengeführt. Wir erhalten also insgesamt vier Schichten. | ||
[[Bild:ML_NN_Entwickeln_3_Loseung.png]] | [[Bild:ML_NN_Entwickeln_3_Loseung.png|center|600px]] | ||
{{Lösung:End}} | {{Lösung:End}} | ||
Aktuelle Version vom 9. April 2024, 12:12 Uhr
Seite zum Projekt Maschinelles Lernen und künstliche Intelligenz des Informatik Diff 10 im Schuljahr 2023/24.
Maschinelles Lernen
"Künstliche Intelligenz" ist derzeit in aller Munde. Dabei ist das, was wir als "Intelligenz" bezeichnen, oftmals gar nicht so schlau und besser mit dem Begriff des "maschinellen Lernens" beschrieben. Denn die Algorithmen "lernen" zwar, ihre Aufgaben effizient (und manchmal sogar besser als Menschen) zu erfüllen, aber sie sind davon abhängig, welche Daten sie zum Lernen bekommen und können ihre Erfahrungen nicht auf andere Bereiche anwenden, als auf die, für die sie trainiert wurden.
Die Theorie der "Künstlichen Intelligen"z ist gar nicht so neu, wie man vielleicht glauben möchte. Aber gerade durch technische Weiterentwicklungen der letzten Jahre und die gestiegene Rechenleistungen ist sie auch an vielen Stellen des Alltags mehr und mehr zu finden.
Arten des maschinellen Lernens
Machine Learning ist ein wichtiger Bestandteil der künstlichen Intelligenz. Dabei kann ein IT-System auf Basis von Algorithmen in Daten selbstständig Muster und Gesetzmäßigkeiten erkennen. So kann maschinelles Lernen mithilfe von Daten Vorhersagen treffen. Außerdem kann es durch Erfahrungen lernen, eigenständig neue Probleme zu lösen.
Verstärkendes Lernen
Verstärkendes Lernen (engl.: reinforcement learning, RL) steht für das selbständige Erlernen einer Strategie, um erhaltene Belohnungen zu maximieren (wobei eine "Bestrafung" als negative Belohnung zu sehen ist). [1]
Überwachtes Lernen
Überwachtes Lernen einer KI findet dann statt, wenn das System versucht, Gesetzmäßigkeiten zu finden (z.B. "Woran erkenne ich ein gesundes Lebensmittel?"). Dabei erhält das KI-System eine Menge von Trainingsdaten, die bereits korrekt "gelabelt" sind (z.B. eine gewisse Datenmenge zu Lebensmitteln, die bereits korrekt als "gesund" oder "ungesund" gelabelt sind). Im nächsten Schritt versucht das System eine Zuordnung zwischen den Daten und den Labeln zu finden. Mit Hilfe von Testdaten kann im Anschluss dieser Lernvorgang überwacht werden. [2]
Unüberwachtes Lernen
Beim unüberwachten Lernen erhält das System Daten, die nicht gelabelt sind. Es versucht, selbstständig in der Menge der Daten gewisse Muster oder Ähnlichkeiten zu finden und so die Daten zu kategorisieren. Auf diesem Weg sind z.B. Auffälligkeiten im Bereich von Buchungen eines Unternehmens oder im Verhalten von Personen zu erkennen. [3]
Spielbäume
Entscheidungsbäume
Neuronale Netze
Neuron
Ein künstliches Neuron ist das kleinste Bauteil eines künstlichen neuronalen Netzes und empfängt Eingaben (Zahlen), multipliziert diese jeweils mit einem individuellen Gewicht für jede Eingangsverbindung, bildet die Summe der gewichteten Eingabewerte und "feuert" dann einen Ausgabewert ab (übergibt ihn an die folgenden Neuronen). Mit "feuern" ist gemeint, dass das Neuron unter einer festgelegten Bedingung die Summe der Eingaben weitergibt und sonst 0. Wann ein Neuron "feuert" kann ganz unterschiedlich festgelegt werden. z.B. könnte eine Bedingung lauten "Wenn die gewichtete Summe größer ein Schwellwert ist" (z.B. > 0).

Vereinfachtes künstliches Neuron
Wir betrachten nun ein vereinfachtes Neuron, dass nur die Eingaben 0 und 1 kennt und immer dann "feuert", wenn die Eingabe über einem festen Schwellwert liegt. In dem Fall wird immer 1 ausgegeben, ansonsten 0.
Mithilfe dieses Neurons wollen wir ein ganz einfaches neuronales Netz erstellen.
Die logischen UND- und ODER-Verknüpfungen kennst Du aus der Programmierung mit Python:
a = inputInt("Gib eine Zahl ein")
if a < 0 or a > 100: # ODER-Verknüpfung
print("Zahl nicht im richtigen Bereich")
elif a > 10 and a < 20: # UND-Verknüpfung
print("Zahl zwischen 10 und 20")
Wie die Verknüpfungen funktionieren, lässt sich anhand einer Tabelle darstellen, in der 1 für True und 0 für False steht. Fülle die beiden Tabellen so aus, dass sie jeweils zur UND- bzw. ODER-Verknüpfung passen:
| e1 | e2 | a |
|---|---|---|
| 0 | 0 | 0() |
| 1 | 0 | 0() |
| 0 | 1 | 0() |
| 1 | 1 | 1() |
| e1 | e2 | a |
|---|---|---|
| 0 | 0 | 0() |
| 1 | 0 | 1() |
| 0 | 1 | 1() |
| 1 | 1 | 1() |
Erkunde auf der Seite inf-schule.de, wie Du ein ODER-Neuron mit einem passenden Schwellwert erstellen kannst.
Bearbeite dann die weiteren Schritte bis zur Zusammenfassung
Neuonenschichten
In einem neuronalen Netz werden Neuronen in Schichten zusammengefasst. Die Eingabeschicht empfängt die Eingabedaten von außen. Die Ausgabeschicht gibt das Ergebnis an. Dazwischen können beliebig viele Neuronenschichten liegen (die "Hidden Layers"), die zur Berechnung des Ergebnisses beitragen.
Wie neuronale Netze lernen
- Bearbeite die Lernstrecke Einführung Neuronale Netze auf inf-schule.de bis zur Zusammenfassung.
- Erstelle neuronale Netzwerke für die ersten beiden Beispiele ( a) und b) ) von Aufgabe 1: https://www.inf-schule.de/KI_im_Unterricht/neuronaleNetze/uebungen
In der letzten Aufgabe hast Du das Netz selbst angelernt. Das Ziel ist es aber, das Netz selbst seine Gewichte finden zu lassen. Also "maschinell lernen" zu lassen. Unter https://link.ngb.schule/nnsim-steinlaus findest Du eine Simulation eines neuronalen Netzes zur Erkennung der Steinlaus aus der letzten Aufgabe.
Erkunde die Simulation, indem Du mehrfach auf "Train" klickst und beobachte, was passiert.
Mit "Animate" kannst Du das Netzwerk automatisiert lernen lassen. Betrachte dabei den Reiter "Error History" und die Grafik links. Was lässt sich beobachten?
Ursprünglich wollten wir ein neuronales Netz Pixel zählen lassen. Unter https://link.ngb.schule/nnsim-pixel wurde das Netz von der Tafel nachgebaut.
- Erkunde auch hier die Simulation und beobachte die Änderungen.
- Studiere anschließend (nachdem das Netz "fertig" gelernt hat) auch den Reiter "Table Input" oben rechts. Was bedeuten die Zeilen in der Tabelle?
Das Netz kann die Trainingsdaten für einen schwarzen Pixel nicht besonders gut abbilden. Wahrscheinlich ist es nicht komplex genug (hat nicht genug Neuronen und Schichten). Ergänze unten eine weitere Schicht und experimentiere mit der Anzahl der Neuronen.
- Wann lernt das Netz, die Trainingsdaten genauer abzubilden?
- Was bedeuten nun die Gewichte der Kanten?
- Wie müsste das Netzwerk für drei oder gar vier Pixel aussehen?
Öffne in einem neuen Fenster playground.tensorflow.org.
Reduziere die "hidden layers" auf 1 und die Neuronen auf 3. Belasse die Auswahl von "Data" auf der kreisförmigen Punktmenge.

Lasse das neuronale Netz schrittweise lernen (der kleine Pfeil neben dem großen "Play"-Button):
- Wie viele Schritte sind nötig, bis "Training loss" weniger als 10% beträgt?
- Interpretiere die Bedeutung der Symbole der Neuronen im "hidden layer" (bewege Deine Maus darüber).
- Experimentiere mit weiteren Eingangsdaten und überprüfe dabei, wie gering die Anzahl der verwendeten Neuronen dabei sein darf.
- Experimentiere mit verschiedenen "Features" und Neuronenanzahlen. Welche Kombinationen funktionieren gut, welche weniger gut? Woran liegt das?
Large Language Models
Die heute wohl bekannteste "künstliche Intelligenz" ist ChatGPT. ChatGPT ist ein "Large Language Model" (LLM). Doch die vermeintliche Intelligenz ist eigentlich nur ein Haufen Mathematik und Wahrscheinlichkeiten, die uns "Intelligenz" vorgaukelt.
Wie ein LLM grundsätzlich funktioniert, wollen wir anhand einer vereinfachten Variante von ChatGPT erkunden.
- Öffne die Seite Soekia.ch. Klicke auf den "Play" Button neben dem Text "Es war einmal ...". Beobachte, was passiert.
- Pausiere die Generierung nach einer Weile. Wie gut ist das Märchen gelungen?
- Wähle nun "Selbst auswählen". Ergänze die bisherige Geschichte um einige Wörter. Klicke dann erneut auf "Selbst auswählen" und lass die K.I. dann die Geschichte "Automatisch fortsetzen".
- Das LLM schreibt ganz passable Märchen. Wie das passiert, kannst Du beobachten, wenn Du oben rechts auf "Schau hinein" klickst. Klicke im Textfeld unten in der Ecke auf den Mülleimer (Text löschen) und starte die Generierung von vorn. Beobachte die rote Spalte. Was passiert hier?
- Pausiere die Generierung und klicke einen der Textauszüge in der roten Spalte an. Du kannst das Wort in den Text einfügen und den Text manuell fortsetzen.
- Kannst Du anhand der gelben und roten Spalte erklären, wie das LLM einen Text generiert?
- Wie geht das Märchen nach "Es war einmal" weiter? Gibt es Auffälligkeiten? Kommt jemals eine Königin in den Märchen vor? Wieso nicht?
- Klicke in der roten Spalte auf "Auswahl anpassen". Experimentiere mit der "Anzahl ausgewählter Wortvorschläge" und der "Temperatur". Wie verändern sich dei generierten Märchen?
Die Textgenerierung von LLMs basiert zu einem großen Teil auf Wahrscheinlichkeiten: "Welches Wort folgt am wahrscheinlichsten auf die bisherigen?"
Diese Wahrscheinlichkeiten werden vom LLM "gelernt" und (bei großen Modellen) in einem neuronalen Netz gespeichert. In unserem vereinfachten Modell sind die Wahrscheinlichkeiten einer Wortkette einfach die Anzahl der Vorkommen im Textkorpus, aus dem das LLM lernt. Rechts siehst Du die 12 Dokumente, aus denen dieses LLM gelernt hat, Märchen zu schreiben. Die Wahl der Texte bestimmt also maßgeblich, wie gut die Texte sind und welche Texte generiert werden können.
Durch eine schlechte Auswahl lassen sich aber LLMs auch leicht falsch anlernen oder gar böswillig manipulieren.
Du hast vielleicht gemerkt, dass die Märchen nach "Es war einmal" immer mit "ein" oder manchmal "eine" weitergehen. Mal sehen, ob wir das ändern können.
Erstelle in der grünen Spalte oben ein "Neues Dokument". Füge den folgenden Text ein:
Es war einmal in einem Wald ein Mann, der hatte drei Söhne. Es war einmal in einem Wald ein altes graues Männlein. Es war einmal in einem Wald ein Müller, der war arm. Es war einmal in einem Wald eine Witwe, die hatte zwei Töchter. Es war einmal in einem Wald ein König, dessen Töchter alle hässlich waren.
Speichere den Text und beobachte, was passiert. Generiere dann ein ganz neues Märchen. Hat sich etwas geändert?
Wähle in der grünen Spalte oben das mittlere Symbol und dann das dritte von oben ("Wettervorhersage"). Bestätige den Dialog und generiere einen neuen Text.
Unser LLM kann nun Wettervorhersagen machen. Aber wir wollen kein schlechtes Wetter. Bringe die K.I. dazu, nur noch gute Vorhersagen zu machen.
Wir bringen dem LLM nun eine ganz neue Textkategorie bei. Lösche alle Dokumente (drittes Symbol oben in der grünen Spalte).
Such Dir eine interessante Seite aus der Wikipedia aus (zum Beispiel die Affen) oder einen Artikel von einem Online-Magazin und kopiere einen Abschnitt des Textes. Beispielsweise
Die Affen (Anthropoidea, Simiae oder Simiiformes), auch als „Eigentliche Affen“, „Echte Affen“ oder „Höhere Primaten“ bezeichnet, sind eine zu den Trockennasenprimaten gehörende Verwandtschaftsgruppe der Primaten. Traditionell wurden sie den „Halbaffen“ gegenübergestellt, jedoch sind sie mit den Koboldmakis näher verwandt als mit den übrigen Vertretern dieser Gruppe. Sie teilen sich in die Neuweltaffen und die Altweltaffen auf, zu denen auch der Mensch gehört. Die Größe der Affen schwankt zwischen dem Zwergseidenäffchen, mit einer Kopf-Rumpf-Länge von rund 12 bis 15 Zentimetern und einem Gewicht von rund 100 Gramm, und den Gorillas, die stehend bis zu 1,75 Meter hoch werden und ein Gewicht von 200 Kilogramm erreichen können, sowie den Menschen mit einer Körpergröße von durchschnittlich 1,60 bis 1,80 Metern, in Einzelfällen auch mehr als 2,00 Metern. Einige Arten haben einen ausgeprägten Geschlechtsdimorphismus, wobei die Männchen mancher Arten doppelt so schwer wie die Weibchen sein können und sich auch in der Fellfarbe unterscheiden können. Ihr Körper ist meist mit Fell bedeckt, dessen Färbung von schwarz über verschiedene Braun- und Grautöne bis zu weiß variieren kann. Die Handflächen und Fußsohlen sind meistens unbehaart, manchmal auch das Gesicht. Die Augen sind groß und nach vorn gerichtet, womit ein guter Gesichtssinn einhergeht. Als Trockennasenprimaten ist ihr Geruchssinn hingegen unterentwickelt. Da die meisten Arten Baumbewohner sind, sind ihre Gliedmaßen an die Lebensweise angepasst. Die Hinterbeine sind fast immer länger und stärker als die Vorderbeine (Ausnahmen sind die Gibbons und die nicht-menschlichen Menschenaffen) und tragen den größeren Anteil der Bewegung. Die Finger und Zehen sind an das Greifen angepasst. Merkmal aller Arten (mit Ausnahme des Menschen) ist die opponierbare (den anderen Zehen gegenüberstellbare) Großzehe. Auch der Daumen ist manchmal opponierbar, bei Arten, die sich hangelnd durch die Äste bewegen, ist er jedoch zurückgebildet. Die jeweils fünf Strahlen der Gliedmaßen (Finger und Zehen) tragen in den meisten Fällen Nägel statt Krallen. Der Schwanz ist meist lang und dient vorrangig als Balanceorgan. Einige Neuweltaffen haben einen Greifschwanz ausgebildet. Bei den Menschenartigen und einigen anderen Arten ist es allerdings zu einer Rückbildung des Schwanzes gekommen.
Erstelle ein neues Dokument im LLM und füge den Text ein. Speichere und lass Dir einen neuen Text generieren.
Ergänze weitere Texte in Deinem Trainingskorpus. Versuche dabei, Dich an eine Textgattung zu halten (Wikipedia Artikel, Sportnachrichten, ...). Welche Texte machen das LLM "besser", welche haben weniger oder sogar einen negativen Effekt?
Lösche alle Dokumente, erstelle ein neues und füge den folgenden Text über unsere Erde aus der Wikipedia ein:
Die Erde ist der dichteste, fünftgrößte und der Sonne drittnächste Planet des Sonnensystems. Sie ist Ursprungsort und Heimat aller bekannten Lebewesen. Ihr Durchmesser beträgt mehr als 12.700 Kilometer und ihr Alter etwa 4,6 Milliarden Jahre. Nach ihrer vorherrschenden geochemischen Beschaffenheit wurde der Begriff der „erdähnlichen Planeten“ geprägt. Das astronomische Symbol der Erde ist ♁ oder 🜨. Da die Erdoberfläche zu etwa zwei Dritteln aus Wasser besteht und daher die Erde vom All betrachtet vorwiegend blau erscheint, wird sie auch Blauer Planet genannt. Sie wird metaphorisch auch als „Raumschiff Erde“ bezeichnet. Die Erde spielt als Lebensgrundlage des Menschen in allen Religionen eine herausragende Rolle als heilige Ganzheit; in etlichen ethnischen, Volks- und historischen Religionen entweder als Vergöttlichung einer „Mutter Erde“ oder personifiziert als Erdgöttin.
Lass erneut einen kurzen Text generieren.
Erstelle nun ein weiteres Dokument und füge den folgenden Satz ein:
Die Erde ist eine Scheibe.
Lass erneut einen kurzen Text generieren.
Beurteile Deine Beobachtungen und welche Folgerungen zu Gefahren von K.I.-Systemen sich daraus ergeben.
Large Language Models arbeiten mit Sprache(n). Man kann allerdings viel mehr Informationen als "Sprache" auffassen, als es Dir vielleicht zunächst in den Sinn kommt. Der Computer kommuniziert beispielsweise in einer Sprache aus 0 und 1. Und es heißt nicht umsonst eine "Programmiersprache". Für ein LLM ist im Grunde alles eine "Sprache", was sich in (Text)Zeichen darstellen lässt.
Etwa dies hier:
L:1/4 M:4/4 |CDEF|G2G2|AAAA|G4|AAAA|G4|FFFF|E2E2|GGGG|C4| M:4/4 |CDEF|G2G2|AAAA|G4|AAAA|G4|FFFF|E2E2|DDDD|C4|
- Öffne die Seite drawthedots.com und erkläre, was der kryptische Text oben bedeutet. Eine weitere Seite ist https://abc.rectanglered.com.
- Informiere Dich über die ABC.
- Lade in unserem vereinfachten LLM die vierte Kollektion an Dokumenten ("Musik in ABC-Notation"). Kopiere probeweise einige der Texte aus den Dokumenten in den ABC-Player und höre sie Dir an.
- Lass Dir ein neues Musikstück generieren. Wie klingen die Kompositonen der K.I.?
Experimentiere mit weiteren Textformen oder Textdokumenten. Webseiten bestehen beispielsweise aus HTML-Quelltext. Du hast selbst schon einige Python-Programme programmiert. Wie wäre es mit einem Abschnitt aus unserem Schulprogramm? Oder ein paar Songtexten?
Unüberwachtes Lernen
Beim unüberwachten Lernen gibt es keine vorher bekannten Trainingsdaten, anhand derer ein Algorithmus lernen kann, sondern es gibt nur eine (meist sehr große) Menge an Daten. Der Algorithmus lernt dann selbstständig, welche Muster die Daten aufweisen und bildet Gruppen an Datenpunkten, die Gemeinsamkeiten haben. Diesen Vorgang nennt man "Clustering".
Aufgrund welcher Informationen die Gruppen ("Cluster") gebildet werden, kann schwer vorhergesagt werden, da die Maschine selber entscheidet, welche Zusammenhänge wichtig erscheinen.
Finde Dich in einer Dreiergruppe zusammen und holt Euch von vorn die Materialien, um die Goldrausch-Aktivität durchzuführen. Ihr benötigt dafür
- eine Landkarte,
- 20 Goldfund-Karten,
- 3 Goldgräber-Figuren.
Goldrausch
Ihr habt drei Grabungsteams zur Verfügung, diese sind durch die Spielfiguren visualisiert. Eure Aufgabe ist es, für jedes der Teams einen bestmöglichen Grabungsort festzulegen. Ein guter Grabungsort liegt möglichst zentral in einem Goldfeld.
Zur Verfügung habt Ihr außerdem eine Reihe von Berichten über Goldfunde in Form von Kärtchen mit x- und y-Koordinate des Fundortes. Mischt diese Kärtchen und legt sie verdeckt als Stapel neben die Karte.
Zieht nun immer ein Kärtchen, überlegt euch, wie ihr dieses verarbeitet, und legt es danach verdeckt auf den Ablagestapel.
Nachdem ihr alle Kärtchen verarbeitet habt, gebt für jedes der drei Grabungsteams x und y Koordinate des bestmöglichen Grabungsortes an! Euch stehen keine weiteren Hilfsmittel zur Verfügung, insbesondere keine Stifte ;).
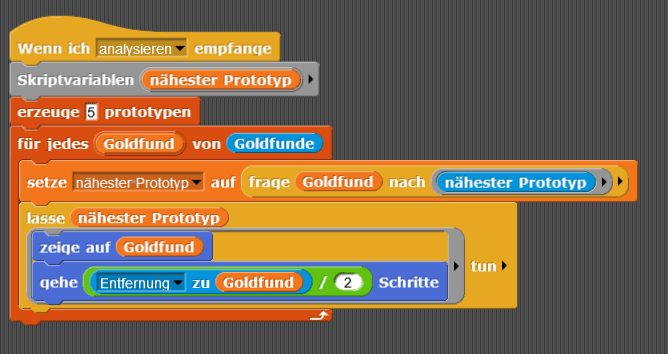
Eine Möglichkeit, einen guten Platz für die Goldgräber zu finden, ist der Learning-Vector-Quantification (LVQ) Algorithmus. Er ist ein mögliches Verfahren des Unsupervised-Learnings.
Implementiere das LVQ Verfahren in Snap! (einer Variante von Scratch).
Öffne dazu die Vorlage unter folgendem Link: https://link.ngb.schule/snap-ai-taskb
Pseudocode zum Algorithmus:
Wenn ich analysieren empfange
Wiederhole für jeden Goldfund
suche nähesten Prototypen zum aktuellen Goldfund (frage den Goldfund)
Lasse den nähesten Goldfund
bewege dich die halbe Entfernung in Richtung des aktuellen Goldfundes
Ende Lasse
Ende Wiederhole
Ende Wenn
Musterlösung:
Übungen zur Vorbereitung der Kursarbeit
Mit den folgenden Übungen kannst Du Dich auf die Kursarbeit vorbereiten.
Themenübersicht
Folgende Themen wurden in der Unterrichtsreihe "Maschinelles Lernen" behandelt:
- #Übungen Grundlagen der KI
- #Übungen Spielbäume
- #Übungen Entscheidungsbäume
- #Übungen Neuronale Netze
- #Übungen Unüberwachtes Lernen
Übungen Grundlagen der KI
- Beschreibe, welche Arten von K.I. es gibt.
- Beschreibe die Bedeutung der Begriffe "Intelligenz" und "Lernen" im Kontext von KI, wie wir sie heute haben.
- Erläutere, warum wir nicht von "Künstlicher Intelligenz" sprechen sollten, sondern von "Maschinellem Lernen".
- Beschreibe, welche Arten des maschinellen Lernens es gibt.
- Man unterscheidet "starke" und "schwache" KI:
- Starke KI wäre insofern nicht von einer menschlichen Intelligenz zu unterscheiden, als dass sie selbstständig lernen kann, jedes Problem zu lösen und sich selbst verbessern könnte. Sie wäre vermutlich intelligenter als ein Mensch, da sie Informationen in viel größeren Mengen verarbeiten könnte, als ein Mensch.
- Schwache KI ist das, was wir heutzutage haben (ChatGPT; selbstfahrende Autos ...) und ist darauf trainiert, eine Aufgabe besonders gut zu lösen. Sie kann aber kein anderes Problem lösen, als das, auf das sie gezielt trainiert wurde. (Ein Schachcomputer kann keine Pfannkuchen backen.)
- Die KIen von heute sind nicht wirklich intelligent, sondern produzieren nur neue Kombinationen aus den Daten, aus denen sie angelernt wurden. Sie können nicht wirklich kreativ sein. Kleine Abweichungen von erwarteten Eingaben können sie oftmals schon aus dem Tritt bringen. Diese KIs haben aber gelernt, ihre Aufgabe zu lösen, indem sie aus vorhandenen Daten Muster erkannt und "verinnerlicht" haben. Dieses Lernen ist teilweise davon abgeguckt, wie wir Menschen lernen.
- "Künstliche Intelligenz" suggeriert, dass es sich um wirklich intelligente Maschienen handelt. Dies ist aber nicht der Fall. Daher passt der Begriff des "maschinellen Lernens" besser.
- siehe oben
Übungen Spielbäume
- Erstelle einen vollständigen Spielbaum zum Nim-Spiel mit fünf Hölzern. (Online-Version des Spiels.)
- Erkläre, wie eine Maschine anhand eines Spielbaums ein Spiel "lernen" kann.
- Erläutere, ob mithilfe eines Spielbaums jedes Spiel "perfekt" gespielt werden kann.
Übungen Entscheidungsbäume
- Entscheide anhand des Entscheidungsbaums, welche Äpfelsorten Früchte tragen werden.
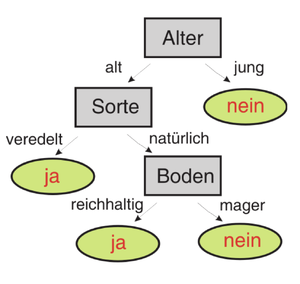
Alter Sorte Boden Trägt Früchte? alt veredelt mager alt natürlich reichhaltig jung veredelt reichhaltig alt natürlich mager alt veredelt reichhaltig - Erstelle anhand der Tabelle mit Trainingsdaten einen Entscheidungsbaum, der entscheidet, ob wir morgen Tennis spielen gehen wollen, oder nicht. Wende dann Deinen Baum auf die Testdaten in der zweiten Tabelle an.
Beurteile dann die Güte Deines Baumes und welche Probleme es gibt.
Welche Rückschlüsse lassen sich aus diesem Beispiel für die Auswahl von Trainingsdaten ziehen?Traininsgdaten Vorhersage Temperatur Feuchtigkeit Wind Tennis Spielen? sonnig heiß hoch schwach nein sonnig heiß hoch stark nein bewölkt heiß hoch schwach ja regnerisch mild hoch schwach ja regnerisch kalt normal schwach ja regnerisch kalt normal stark nein bewölkt mild hoch stark ja sonnig mild hoch schwach nein sonnig kalt normal schwach ja regnerisch mild normal schwach ja sonnig mild normal stark ja bewölkt heiß normal schwach ja bewölkt kalt normal stark ja regnerisch mild hoch stark nein Testdaten Vorhersage Temperatur Feuchtigkeit Wind Tennis spielen? sonnig mild normal stark bewölkt mild normal schwach regnerisch heiß hoch stark bewölkt kalt normal schwach sonnig mild normal schwach bewölkt kalt gering schwach sonnig heiß gering schwach - Auf der Seite inf-schule.de findest Du eine digitale Version der Lebensmittelkarten aus dem Unterricht. Durchlaufe den Pfad und entwickele einen Entscheidungsbaum unter der Fragestellung "Welche Lebensmittel sind besonders lecker?" (anstatt "welche sind gesund").
Welche Kriterien gelten für die Wahl einer Entscheidungskategorie und eines guten Schwellwerts?

-
Alter Sorte Boden Trägt Früchte? alt veredelt mager ja alt natürlich reichhaltig ja jung veredelt reichhaltig nein alt natürlich mager nein alt veredelt reichhaltig ja - Bei der Auswahl der Trainingsdaten ist es wichtig alle möglichen Ausprägungen der Merkmale in ausreichender Menge zu berücksichtigen. Gibt es Ausprägungen, die in den Trainingsdaten fehlen, dann kann ein Entscheidungsbaum auch nicht lernen, welche Entscheidungen bei dieser Ausprägung getroffen werden müssen. Im Beispiel kommt die Ausprägung "gering" des Merkmals "Feuchtigkeit" nicht in den Trainingsdaten vor, aber in den Testdaten schon. Dies kann zu unvorhergesehenen / ungewünschten Ergebnissen führen.
- ...
Übungen Neuronale Netze
- Gib jeweils Gewichte und Schwellwerte an, sodass das gezeigte Neuron bei möglichen Eingaben
0und1für jeden der drei Eingänge- ein
UND-Gatter nachbildet, - ein
ODER-Gatter nachbildet, - nur feuert, wenn beide Eingaben
0sind. - Beschreibe allgemein, wie in den drei Fällen die Gewichte und Schwellwerte gewählt werden müssen.
- ein
- Erstelle zu den Bildern jeweils ein künstliches neuronales Netz, das Datenpunkte innerhalb des rot hinterlegten Bereichs erkennt. (Klicke die Bilder an, um eine größere Version zu sehen.)

![[1]](https://www.inf-schule.de/content/120_KI_im_Unterricht/2_LernendeSysteme/3_lernarten/verstaerkendesLernen.png){kind=link}
![[2]](https://www.inf-schule.de/content/120_KI_im_Unterricht/2_LernendeSysteme/3_lernarten/ueberwachtesLernen.png){kind=link}
![[3]](https://www.inf-schule.de/content/120_KI_im_Unterricht/2_LernendeSysteme/3_lernarten/unueberwachtesLernen.png){kind=link}
{kind=link}



- Erstelle drei, vier bzw. zwei lineare Gleichungen ([math]\displaystyle{ y = m dot x + a }[/math]), die den roten Bereich einschließen.
- Forme die vier Gleichungen in drei oder vier passende Ungleichungen um (im dritten Fall sind es auch vier!).
- Verknüpfe die vier Ungleichungen mit passenden
UND-Neuronen (siehe Aufgabe 1). Im dritten Fall musst Du noch ein zusätzlichesODER-Neuron benutzen.
Drei Gleichungen aufstellen:
- [math]\displaystyle{ y = x + 1 }[/math]
- [math]\displaystyle{ y = -0,5x + 3 }[/math]
- [math]\displaystyle{ y = -7x + 35 }[/math]
Zu drei Ungleichungen umformen:
- [math]\displaystyle{ x - y \gt -1 }[/math]
- [math]\displaystyle{ 0,5x + y \gt 3 }[/math]
- [math]\displaystyle{ -7x - y \gt -35 }[/math]

Vier Gleichungen aufstellen:
- [math]\displaystyle{ y = 0,25x + 4 }[/math]
- [math]\displaystyle{ y = 0x + 2 }[/math]
- [math]\displaystyle{ y = -2,5x + 5 }[/math]
- [math]\displaystyle{ y = 2,5x - 5 }[/math]
Zu vier Ungleichungen umformen:
- [math]\displaystyle{ 0,25x - y \gt -4 }[/math]
- [math]\displaystyle{ 0x + y \gt 2 }[/math]
- [math]\displaystyle{ 2,5x + y \gt 5 }[/math]
- [math]\displaystyle{ -2,5x + y \gt -5 }[/math]

Zwei Gleichungen aufstellen:
- [math]\displaystyle{ y = 0,5x + 0,5 }[/math]
- [math]\displaystyle{ y = -2x + 8 }[/math]
Zu vier Ungleichungen umformen, von denen jeweils zwei die beiden Dreiecksflächen einschließen:
- [math]\displaystyle{ y \gt 0,5x + 0,5 \Leftrightarrow -0,5x + y \gt 0,5 }[/math]
- [math]\displaystyle{ y \lt -2x + 8 \Leftrightarrow -2x - y \gt -8 }[/math]
- [math]\displaystyle{ y \lt 0,5x + 0,5 \Leftrightarrow 0,5x - y \gt -0,5 }[/math]
- [math]\displaystyle{ y \gt -2x + 8 \Leftrightarrow 2x + y \gt 8 }[/math]
Die erste und zweite und die zweite und dritte Ungleichung schließen jeweils eine der beiden Dreiecksflächen ein. Sie werden durch ein UND-Neuron verknüpft. (Da immer alle Neuronen einer Schicht eine Verbindung zu allen Neuronen der nachfolgenden Schicht haben, setzen wir die Gewichte der beiden "unnötigen" Verbindungen einfach auf 0.)
Der Output der beiden UND-Neuronen wird durch ein ODER-Neuron zusammengeführt. Wir erhalten also insgesamt vier Schichten.

Übungen Unüberwachtes Lernen
- Beschreibe das Vorgehen beim "Learning-Vector-Quantification" Verfahren, um einen "Prototypen" schrittweise einem Cluster von Daten anzunähern.